
Prompt caching
BMO does not add a second, client-side prompt “cache” in front of models. Savings and routing come from each provider’s API. BMO surfaces cache-related usage in costs and observability, and can optionally derive an OpenAI prompt cache key for coordination across turns.
Use this page to answer three operator questions:
- Is my request cache-shaped before it leaves BMO?
- Did the provider report a cache read or cache creation?
- Did that cache hit also improve the user experience, especially time to first output or completion time?
flowchart LR
A["Stable prompt + tool prefix"] --> B["BMO shapes provider request"]
B --> C{"Provider usage reports cache tokens?"}
C -->|"no"| D["Cache-shaped, not proven"]
C -->|"yes: read or creation tokens"| E["Working-cache evidence"]
E --> F{"Timing improves?"}
F -->|"yes"| G["Cost + latency benefit"]
F -->|"no"| H["Cost evidence only"]
Working-cache indicators
Section titled “Working-cache indicators”Treat the UI as an evidence ladder. Start with the live /cache surface while
you are working, then use proof artifacts when you need a shareable result.
| Surface | Working-cache indicator | What it tells you | Caveat |
|---|---|---|---|
| Session costs and agent debugger | Non-zero cache read or cache write / creation tokens | The provider mapped cache usage for that turn | Provider dashboards remain the source of billing truth |
/cache in the TUI | state: up, live runtime observed, recent cacheproof.* events | BMO can see live app posture and the recent metadata ring | Recent events are metadata-only and bounded |
bmo config show-cache | Effective affinity, routing, Anthropic breakpoint, and env-disable posture | Shell-friendly config posture | This is out of process, so it does not prove live recent events |
get_prompt_cache_status / bmo_get_prompt_cache_status | Same structured posture used by agent-native and MCP callers | Machine-readable status for tools and dashboards | Requires the caller to bind the intended session when session scope matters |
bmo cache proof artifact | pass verdict plus measured repeat with provider cache reads | Shareable proof that a repeated workload hit the provider cache | Timing is recorded separately and is not proof by itself |
bmo runtime latency --cache-proof ... | Cache/control timing appears in the provider row | Whether a cache hit helped perceived latency | Routing remains opt-in and proof-backed |
The quickest live readout looks like this:
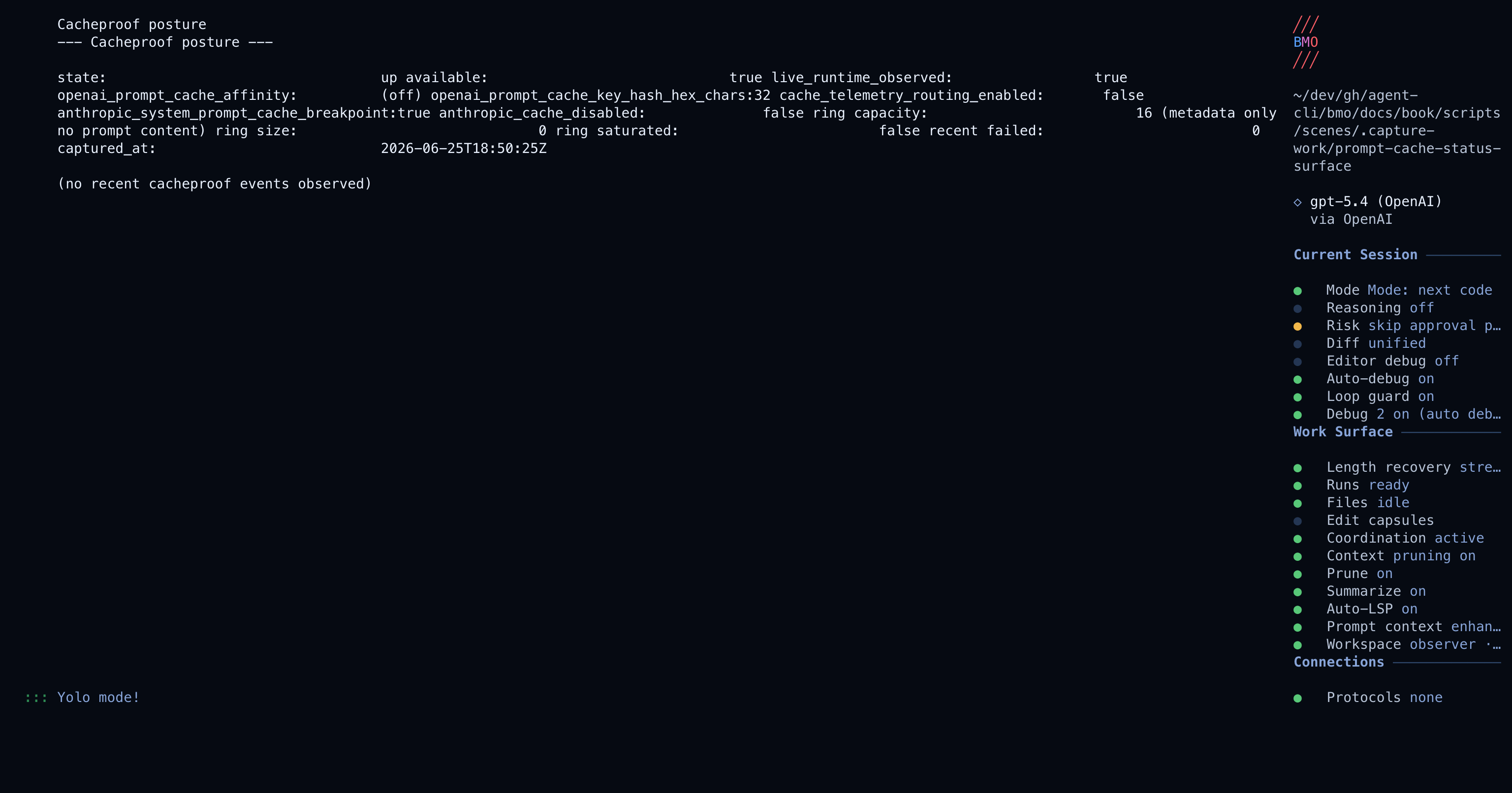
--- Cacheproof posture ---
state: up available: true live_runtime_observed: true openai_prompt_cache_affinity: session_tools cache_telemetry_routing_enabled: false anthropic_system_prompt_cache_breakpoint:true anthropic_cache_disabled: false ring capacity: 32 (metadata only; no prompt content) ring size: 2 recent failed: 0Good signs are state: up in the TUI, a configured affinity or provider cache
breakpoint that matches your model family, and recent events without failures.
If the ring is empty, BMO has not observed recent cache-proof telemetry in the
current live process. If usage counters stay zero, the request may be
cache-shaped but not yet a provider-reported hit.
Configuration patterns
Section titled “Configuration patterns”Choose the smallest pattern that matches how you work.
| Pattern | Use when | Configuration | UX expectation |
|---|---|---|---|
| Provider defaults | You want provider-managed implicit caching only | No BMO prompt-cache option required | Watch provider usage, debugger costs, and proof artifacts |
| OpenAI session affinity | Long interactive sessions reuse a stable tool/prompt prefix | options.openai_prompt_cache_affinity = "session_tools" | Related turns in one session get the same prompt_cache_key until the tool set changes |
| OpenAI recipe affinity | Scheduled or repeatable recipe runs share the same stable recipe/tool prefix | options.openai_prompt_cache_affinity = "recipe_tools" | Clean reruns of the same recipe can reuse affinity without depending on one session id |
| Anthropic-family breakpoints | Anthropic, Bedrock Converse Claude, or Vercel Anthropic models use BMO’s default markers | Leave options.anthropic_system_prompt_cache_breakpoint enabled | Stable system prefix and final tool tail are marked separately |
| Disable Anthropic markers | A gateway or model rejects cache_control / cachePoint | BMO_DISABLE_ANTHROPIC_CACHE=true | No Anthropic tool or system prompt cache markers are attached |
| Gemini explicit cache | You already manage a named cachedContents resource | Add cached_content = "cachedContents/..." under provider provider_options | BMO sends the named resource; you manage TTL, refresh, and deletion |
| Proof-backed routing | You have proof that cache reads also improve timing for a workload | Enable options.cache_telemetry_routing with proof artifacts and candidates | BMO can make a run-scoped route only when the proof and current selection match |
Example OpenAI session pattern:
[options]openai_prompt_cache_affinity = "session_tools"openai_prompt_cache_key_hash_hex_chars = 32Example repeatable recipe pattern:
[options]openai_prompt_cache_affinity = "recipe_tools"Example proof-backed routing pattern:
[options.cache_telemetry_routing]enabled = trueproof_artifacts = [".bmo/evidence/prompt-cache-proof-openai.json"]candidate_selectors = ["small", "openai/gpt-5"]Observing cache impact
Section titled “Observing cache impact”- Usage fields may include cache read and cache write (creation) counters when the provider maps them. These show up in session cost totals and the agent debugger, consistent with the provider’s own dashboards.
- Prompt-budget snapshots also expose cache eligibility and presence on the final provider envelope: OpenAI cache key presence, Anthropic cache marker counts, approximate Anthropic cacheable system-prefix size, Gemini cached-content references, and whether usage is reported separately. These fields do not claim a cache hit; they explain whether the request was cache-shaped before provider execution.
- With debug logging enabled, a turn that attributes non-zero cache
read or cache creation tokens may emit a structured
LLM cache usage non-zero for generationline (session id, provider, model, counts). See Troubleshooting and your host’s log-level controls (for exampleBMO_LOG_LEVEL). - For empirical proof, run
bmo cache proof. Existing-run mode summarizes repeated--run-idvalues without provider calls. Live mode requires--live-providerand a prompt, performs a warm-up plus measured repeats, and writes a redacted JSON artifact under.bmo/evidence/by default. Apassverdict requires provider-reported cache reads on a measured repeat plus a comparable prior iteration with the same provider, model, and stable-prefix or prompt-shape fingerprint; timing is recorded but does not prove cache leverage by itself. bmo cache proof --tool-surface noneenforces a toolless proof posture for the first provider request. If prompt-budget evidence sees effective tools, provider-envelope tools, or tool-schema tokens under that posture, the proof reportstool_surface_mismatchinstead of treating the run as cache or timing evidence.
Inspect status surfaces
Section titled “Inspect status surfaces”bmo config show-cachereports the effective prompt-caching config posture from the shell. It is intentionally config-only and does not claim access to the live in-process recent-event ring./cachein the TUI renders the live app-backed posture plus bounded recentcacheproof.*metadata.- Agent-native and MCP consumers can use
get_prompt_cache_statusandbmo_get_prompt_cache_statusfor the same structured live posture. list_recent_cache_eventsremains the lower-level raw ring export when you need event-by-event metadata instead of the summarized posture.
OpenAI and Azure OpenAI (native path)
Section titled “OpenAI and Azure OpenAI (native path)”- Providers describe prefix stability and best-effort reuse. Optional
prompt_cache_keyin provider options can help align requests that share a long stable prefix. You can setprompt_cache_keyunder provider and modelprovider_options(Fantasy parses the OpenAI-typed map). - BMO opt-in key derivation (default off): set
options.openai_prompt_cache_affinity = "session_tools"for interactive sessions or"recipe_tools"for repeatable recipe runs. BMO then setsprompt_cache_keyto a deterministicbmo:-prefixed hash of either the session id plus sorted allowed tool names, or the active recipe identity plus sorted tool names. The key rotates when that stable identity changes. Adjust the hex length withoptions.openai_prompt_cache_key_hash_hex_chars(8–64 hex characters, default 32 when unset or zero). - A manually configured
prompt_cache_keyinprovider_optionsis left unchanged; BMO will not override it. - Recipe-scoped keys are trust-scoped to the current BMO workspace/config. They are an affinity hint for the provider, not a client-side cache and not a cross-user data-sharing mechanism.
- Optional
prompt_cache_retention("in_memory"or"24h") can be set in the same mergedprovider_optionsmap for Chat Completions and Responses; it is passed through Fantasy to the OpenAI API (see OpenAI prompt-caching docs for semantics and availability). - Azure OpenAI and other gateways can differ: treat cache hits, keys, and retention as best-effort and confirm against that provider’s docs.
Anthropic, Bedrock (Converse), Vercel Anthropic
Section titled “Anthropic, Bedrock (Converse), Vercel Anthropic”- Caching is driven by
cache_controlon message/tool blocks. BMO attachesephemeralto the last tool in the final filtered tool list so the stable tool tail matches the tools actually sent. If adaptive filtering leaves no tools, BMO does not set a tool marker (no panic). Reordering tools with the same set changes which tool is last, so a different tool carries the marker—this is expected. - When the system-prompt cache breakpoint is enabled, BMO also splits the system
prompt into stable and volatile blocks and marks the stable block as
ephemeralfor Anthropic-family providers. Cache stability is classified separately from shedding priority, so high-priority live state such as the current run or active plan stays outside the cache-marked block. - Set
BMO_DISABLE_ANTHROPIC_CACHE=trueto disable attaching that marker. See Environment variables.
Google Gemini
Section titled “Google Gemini”- Implicit context caching (often on newer models) can reduce cost without a separate resource name; follow Google’s product docs.
- Explicit
cachedContentsresources are created, updated, and deleted out of band; pass acached_contentname in merged providerprovider_options(Fantasygoogleparse) when you have a resource. Optional:bmo cache gemini create --from-prompt-snapshot(seebmo cache gemini -h) prints a line you can paste, using a Gemini Developer API key (GOOGLE_API_KEYorGEMINI_API_KEY). Managing TTL, minimum cache size, and cost for stored caches is the operator’s responsibility; BMO does not run a long-lived automatic cache janitor for Gemini by default.
For contributors: Code alignment, edge cases, system-prompt cache rationale, and Gemini cached-content implementation background are in the repository topics
prompt-caching.mdandgemini-cached-content.md.